跳表
第01部分 跳表
数据结构里面一种常见的结构是map,我们知道map的key是不允许重复,根据key的映射,可以快读找到Value的值。这种结构恰恰就是词典结构(dictionary)。由于基础的数据结构已经学习过Set和Map,这部分课程里面就只讲述了跳表和 BloomFliter两种数据结构。这两个数据结构也是KV-store课程项目需要使用的。BloomFliter并不能算一个严格的字典数据结构,但是它可以应用到字典数据结构的去重机制中,例如Redis。
跳转表(skip list)结构的初衷,正是在于试图找到另外一种简便直观的方式,来完成查找任务。具体地,跳转表是一种高效的词典结构,它的定义与实现完全基于有序列表结构,其查询和维护操作在平均的意义下均仅需 时间。
一、跳表的逻辑结构
跳转表的宏观逻辑结构如图所示。
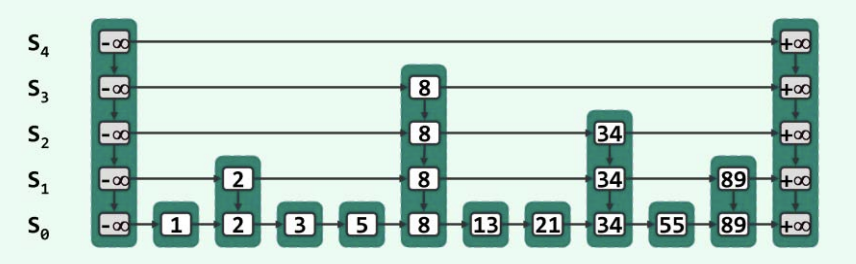
- 其内部由沿横向分层、沿纵向相互耦合的多个列表 组成, 称作跳转表的高度。
- 每一水平列表称作一层(level),同层节点都按关键码排序。
- 层次不同的节点可能沿纵向组成塔(tower),同一塔内的节点的Key-Val都是一样的(说百了一个塔就是个大的数据节点,这个数据节点高度可高可低)
- 塔的第一个节点是 起始节点,里面的值相当于存储的负无穷,最后一个节点是 终止节点,存储正无穷。此外塔的起始节点、终止节点的高度都必须保证覆盖整个跳表的所有楼层!
- 跳表的一个塔就是个大的数据节点,他高度如何确定呢?抛硬币,从一层楼开始增长
- 概率 增加一层,然后继续抛硬币。
- 概率 不再增加高度。
- 为了防止无限增长,一般会有一个最大层的限制。
二、跳表的增删改查
1)查找/修改
跳表的查找首先可以从起始节点开始。准确的说是 起始节点的最高楼层 开始查找。假设我们要找的记作
- 检查当前楼层 的下一个节点的位置对应的Key,计做
- 如果 ,可以跳过去(把指针指向下一个节点!)
- 如果 ,说明已经找到
- 如果 ,继续下楼
- 如果没有下一层了,说明查找失败。
当然如果是修改,那就把查找出来的节点的值修改覆盖即可。
2)插入
- 首先要检查要插入的节点是否已经存在,如果已经存在就不需要插入了!查找的时候需要记录路径(特别是每一层楼经过的最后一个节点!例如查找4的时候, 层经过的最后一个节点是2, 层经过的最后一个节点是3,其余的是负无穷)
- 然后创建一个塔(就是个大的数据节点),并用随机化的方法确定他的高度(以下图为例,插入4的高度假定是3层,从 到 )。
接下来我们要处理好新插入节点和前面的关系、和后面的关系。这样才保证连通嘛!就回忆我们单链表的时候,插入节点要接入前面的,连上后面的。
- 根据刚刚的路径,把路径里面:对应楼层的最后一个节点接入到新插入的塔里面对应的位置( 层经过的最后一个节点是2,就把这个 层的2的下一个节点指向新插入的4,其他的同理。 层因为高度太高,所以不需要考虑。)
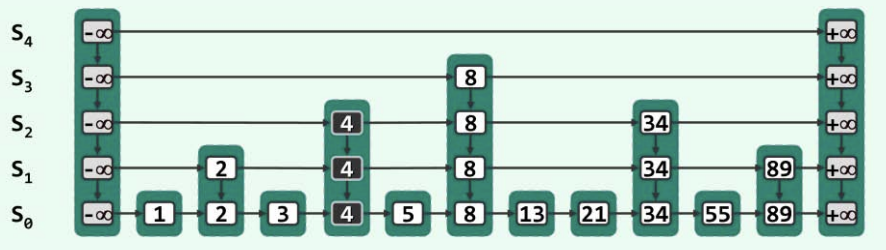
- 然后处理后继的问题。用一个指针
pointer指向5这个节点,然后首先把第0层的链接上去。 - 之后,移动指针
pointer(策略:如果能往上层移动,就往上,否则向右移动) - 指针每次移动到一个新的楼层的时候,需要把新插入的节点(4)对应楼层节点的后继链接到
pointer - 如果
pointer移动到的楼层超过了新插入节点的最高楼层,就可以停止了
3)删除
假设我们要删除下面跳表里面的4这个节点(就是我们刚刚插入的节点)
- 删除一个节点前,首先查找节点是否存在。查找的时候需要 记录路径(特别是每一层楼经过的最后一个节点!例如查找4的时候, 层经过的最后一个节点是2, 层经过的最后一个节点是3,其余的是负无穷)
- 用一个指针
pointer指向删除目标后面直接相连的,也就是5这个节点, - 先把第 层的节点3和5连接起来。然后删除节点4,释放这个塔占用的所有内存。
- 之后,移动指针
pointer(策略:如果能往上层移动,就往上,否则向右移动) - 指针每次移动到一个新的楼层()的时候,需要把 记录路径中 第层经过的最后一个节点的后继链接到
pointer(例如, 层的2号节点应该连接到8, 层的2号节点也应该连接到8) - 如果
pointer移动到的楼层超过了已经删除节点的最高楼层,就可以停止了
三、跳表的时空复杂度
1)空间复杂度
先说空间复杂度,就是 。有人可能觉得很荒谬,怎么可能呢?
- 首先,Level-0层有n个节点吧!
- 然后,根据增长楼层概率,Level-1层应该有 个节点
- 根据增长楼层概率,Level-2层应该有 个节点
- 求和, 个节点!
2)时间复杂度
关于时间度,我们得从跳表这个高度说起。假如不限制高度,那么理论是level-0有 个节点,根据 的概率增长,那么level-1有 个节点,最高层level-k有 个节点(一个负无穷,一个正无穷),
然后考虑查找的时间复杂度的时候,我们可以把每一步看成一个时间复杂度的消耗(无论是往右走,还是往下走)。在每一层中,横向走的步数最多是 。为什么呢:
请看下图的第 级别索引,这个跳表可以说是比较规则化的, 的情况,我们可以看到每一层横向走的最多是一步(为什么?如果走两步的话,那上一层第 级的时候为什么不直接跳转呢?按照这种思想可以理解)
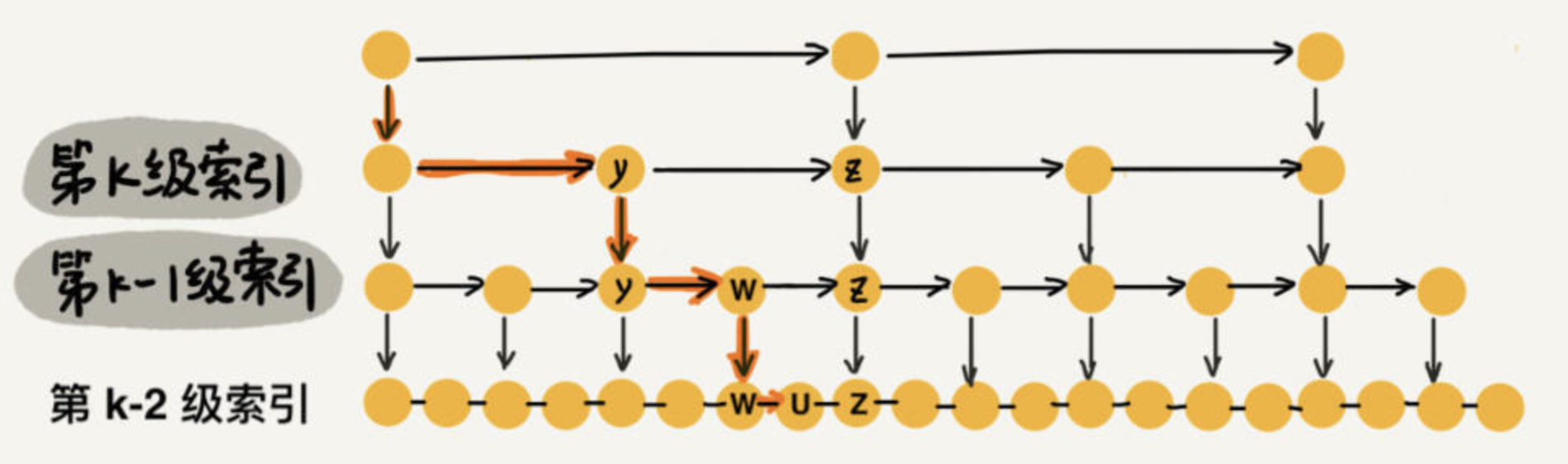
所以在每一层中,横向走的步数最多是 ,一共是 层,所以综合时间复杂度为:
并且可以证明 的时候,时间复杂度最小!(作业题)。
所以插入的时间复杂度 。至于删除和插入的时间复杂度,本质都需要经过查找这一个步骤,其余的步骤大同小异,所以不会有其他的时间复杂度的影响。
四、代码
下面是我在kv-store课程项目使用的跳表。
#pragma once
#include <vector>
#include <ctime>
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <climits>
#include <cassert>
#include <map>
#include <list>
#include "config.h"
// 三种节点类型
const int nodeType_Head = 1;
const int nodeType_Data = 2;
const int nodeType_End = 3;
const int MAX_Level = 8;
const double Jump_Probaility = 0.5;
// 跳表的节点,包括四种类型的数据:右侧节点、上层节点、当前节点的Key和Val
template<typename K, typename V>
struct Node{
K key;
V val;
int type;
std::vector<Node<K, V>*> next;
// 默认的构造函数
Node(){};
// 数据节点的构造函数
Node(K setKey, V setVal, int height){
this->key = setKey;
this->val = setVal;
this->type = nodeType_Data;
for (int i = 0; i < height; i++)
{
next.push_back(NULL);
}
};
// 首部/尾节点的构造函数
Node(int setType){
this->type = setType;
}
~Node(){};
};
template<typename K, typename V>
class Skiplist {
private:
size_t size;
Node<K, V> *head;
int randomLevel();
// 增删查节点的函数
Node<K,V>* insertNode(K elemKey, V elemVal);
Node<K,V>* findNode(K elemKey);
void deleteNode(K elemKey);
public:
Skiplist();
~Skiplist();
// 增删查节点的函数
Node<K,V>* insert(K elemKey, V elemVal);
Node<K,V>* find(K elemKey);
void remove(K elemKey);
void copyAll(std::list<std::pair<K, V> > &list);
size_t getSize();
void clear();
void tranverse();
};
// 产生一个随机的楼层,返回一个大于1,小于等于max level的Int
template<typename K, typename V>
int Skiplist<K,V>::randomLevel(){
int level = 1;
while(level < MAX_Level && (rand() * 1.0 / INT_MAX) <= Jump_Probaility){
level ++;
}
return level;
}
// 初始化一个跳表
template<typename K, typename V>
Skiplist<K,V>::Skiplist(){
srand(time(NULL));
// 初始化一个跳表,创建头节点
head = new Node<K, V>(nodeType_Head);
// 创建尾部节点
Node<K, V> *end = new Node<K, V>(nodeType_End);
// 让头部节点的每一层都指向尾部节点
for(int i = 0; i < MAX_Level; i++){
head->next.push_back(end);
end->next.push_back(NULL);
}
// 设置,数据的大小为0
this->size = 0;
}
// 销毁一个跳表
template<typename K, typename V>
Skiplist<K,V>::~Skiplist(){
// 删除尾巴节点、head节点
delete head->next[0];
delete head;
}
// 插入节点[或者编辑一个已有的节点]
template<typename K, typename V>
Node<K,V>* Skiplist<K,V>::insertNode(K elemKey, V elemVal){
std::map<int, std::vector<Node<K,V>*> > findPath;
// 如果这个节点已经存在,根据要求需要替换里面的数据
Node<K,V>* tryFind = this->findNode(elemKey);
if(tryFind != NULL){
tryFind -> val = elemVal;
return tryFind;
}
// 反之,可以放心的新建节点:
int newNode_level = randomLevel();
Node<K,V>* newNode = new Node<K,V>(elemKey, elemVal, newNode_level);
Node<K,V>* iter = head;
// 这个while循环是需要把迭代器移动到【要插入位置的前一个节点】!
// 比如新的节点要插入到 A 和 B 之间,就把iter移动到 A。
while(iter->next[0]->type != nodeType_End){
bool ifJump = false;
// 遍历当前迭代器的楼层
for(int i = iter->next.size() - 1; i >= 0; i--){
findPath[i].push_back(iter);
Node<K,V>* level_next = iter->next[i];
assert(level_next != NULL);
// 如果当前层指向的是End节点,下楼继续找
if(level_next->type == nodeType_End)
continue;
// 如果当前层指向的数据层的数据小于我们要插入的,执行跳跃操作
// 移动迭代器,到下一个节点
if(level_next->key < elemKey){
iter = level_next;
ifJump = true;
findPath[i].push_back(iter);
break;
}
// 如果当前层指向的数据层的数据大于我们要插入的,老老实实继续下楼
// 啥都不要做,相当于continue
}
// 如果从最高楼下楼到最低楼,都没有执行跳跃操作,说明当前节点
// 每一个楼层的指向的节点,不是End节点就是比 elemKey 要大的
// (不可能等于,前面已经排查了等于的情况)
// 这时候说明,新的节点就插入在iter后面就可以了!
if(!ifJump)
break;
}
// iter 是经过搜索的得到的目标指针,因为涉及到链表断开重链接,所以必须把两头都拿好!
Node<K,V>* iterNext = iter->next[0];
// -------- ---------- ---------------------
// | | | | | |
// | iter | -> | newNode | -> | iterNext |
// | | | | | |
// -------- -------- ---------------------
// 更新上一个节点的 next 容器,需要把较低高度的 next 容器里面的指针,指向新的节点
// 上一个节点的 next 容器较高的高度的 next 容器里面的指针,不需要任何操作
// [分界线]? 新节点的高度及其以下的,就是较低高度,反正就是更高高度
for(int i = 0; i < std::min(newNode_level, (int)iter->next.size()); i++){
iter->next[i] = newNode;
}
// 更新路径上的,可以到达新节点的楼层
for(auto mapIter = findPath.begin(); mapIter != findPath.end(); mapIter++){
// 从小到大遍历经过的路径容器
int level = mapIter->first;
// 如果层数超过了newNode的层数,退出
if(level >= (int)newNode->next.size())
break;
// 寻找每一层最接近那个新插入的节点的节点
Node<K,V>* levelLastNode = mapIter->second[mapIter->second.size() - 1];
// 把这个节点的后继设为新节点。
levelLastNode->next[level] = newNode;
}
// 当新插入节点的高度比新插入节点后面的那个节点要高的时候,高出去的那一部分要指向后面的节点
// 所以,还需要更新新插入节点的 next 容器!
for(int i = 0; i < newNode_level; i++){
// 从底层往上面爬楼,当前的这一层楼,已经超过iterNext的楼层数量 i > iterNext->next.size() - 1
while(iterNext->type != nodeType_End && i + 1 > (int)iterNext->next.size()){
// 执行 iterNext 的跳跃操作!
// 是否会丢失?不会,因为我们是从下往上更新的,不需要担心丢失原来的iterNext
iterNext = iterNext->next[iterNext->next.size() - 1];
}
newNode->next[i] = iterNext;
}
this->size = this->size + 1;
return newNode;
}
// 查找节点,不存在就返回NULL
template<typename K, typename V>
Node<K,V>* Skiplist<K,V>::findNode(K elemKey){
Node<K,V>* iter = head;
// 借鉴插入的思路即可,但是略有不同
// 这个while循环是需要把迭代器移动到【搜索的节点】!
// 比如新的节点要插入到 A 和 B 之间,就把iter移动到 A。
while(iter->next[0]->type != nodeType_End){
bool ifJump = false;
// 遍历当前迭代器的楼层
for(int i = iter->next.size() - 1; i >= 0; i--){
Node<K,V>* level_next = iter->next[i];
assert(level_next != NULL);
// 如果当前层指向的是End节点,下楼继续找
if(level_next->type == nodeType_End)
continue;
// 如果当前层指向的数据层的数据小于我们要查找的,执行跳跃操作
// 移动迭代器,到下一个节点
if(level_next->key < elemKey){
iter = level_next;
ifJump = true;
break;
}
// 如果发现下一个节点就是我要找的
else if(level_next->key == elemKey){
return level_next;
}
// 如果当前层指向的数据层的数据大于我们要插入的,老老实实继续下楼
// 啥都不要做,相当于continue
}
// 如果从最高楼下楼到最低楼,都没有找到
// 每一个楼层的指向的节点,不是End节点就是比 elemKey 要大的
// 这时候说明,要找的节点恰好应该排在iter后面,但是后面又没有
if(!ifJump)
break;
}
// 经过查找没有找到,返回NULL
return NULL;
}
// 删除节点
template<typename K, typename V>
void Skiplist<K,V>::deleteNode(K elemKey){
std::map<int, std::vector<Node<K,V>*> > findPath;
// 如果这个节点已经存在,根据要求需要替换里面的数据
Node<K,V>* delNode = this->findNode(elemKey);
if(delNode == NULL)
return;
// 开始查找
Node<K,V>* iter = head;
// 同样参考之前写的find的代码,但是删除的时候需要注意,【必须把目标节点的前一个节点拿下!】
// 这个while循环是需要把迭代器移动到【要删除位置的前一个节点】!
// 比如 A -> B, 要删除B,就把iter移动到A
while(iter->next[0]->type != nodeType_End){
bool ifJump = false;
// 遍历当前迭代器的楼层
for(int i = iter->next.size() - 1; i >= 0; i--){
findPath[i].push_back(iter);
Node<K,V>* level_next = iter->next[i];
assert(level_next != NULL);
// 如果当前层指向的是End节点,下楼继续找
if(level_next->type == nodeType_End)
continue;
// 如果当前层指向的数据层的数据小于我们要查找的,执行跳跃操作
// 移动迭代器,到下一个节点
if(level_next->key < elemKey){
iter = level_next;
ifJump = true;
findPath[i].push_back(iter);
break;
}
if(level_next->type == nodeType_Head){
std::cout << "error! head again\n" << iter->key << '\n';
this->tranverse();
exit(0);
}
// 这里和刚刚的逻辑又不同了,因为哦们要找target节点的前面的一个
// 【!注意!】如果到了第0层,并且下一个就是elemKey,这时候强制退出循环,我们已经找到
// 【!注意!】如果在比较高的一层,比如第3层,发现下一个就是elemKey,那这个时候,我们什么也不用做,下楼
if(i == 0 && level_next->key == elemKey){
ifJump = false;
break;
}
// 如果当前层指向的数据层的数据大于我们要查找的,老老实实继续下楼
// 啥都不要做,相当于continue
}
if(!ifJump)
break;
}
// 经过while之后,可以肯定iter->next[0] == delNode
assert(iter->next[0] == delNode);
// -------- ---------- ---------------------
// | | | | | |
// | iter | -> | delNode | -> | delNodeNext |
// | | | | | |
// -------- -------- ---------------------
Node<K,V>* delNodeNext = delNode->next[0];
for(long unsigned int i = 0; i < std::min(delNodeNext->next.size(), iter->next.size()); i++){
iter->next[i] = delNodeNext;
}
for(auto mapIter = findPath.begin(); mapIter != findPath.end(); mapIter++){
// 从小到大遍历经过的路径容器
int level = mapIter->first;
// 寻找每一层最接近那个新插入的节点的节点
Node<K,V>* levelLastNode = mapIter->second[mapIter->second.size() - 1];
while(delNodeNext->type != nodeType_End && level + 1 > (int)delNodeNext->next.size()){
delNodeNext = delNodeNext->next[delNodeNext->next.size() - 1];
}
// 把这个节点的后继设为新节点。
levelLastNode->next[level] = delNodeNext;
}
delete delNode;
this->size = this->size - 1;
}
// 获取表格里面的数据节点的个数
template<typename K, typename V>
size_t Skiplist<K,V>::getSize(){
return this->size;
}
// 清空表格里面的数据节点,不包括头结点、尾部节点
template<typename K, typename V>
void Skiplist<K,V>::clear(){
Node<K,V>* iter = head;
Node<K,V>* del_node;
while(iter->type != nodeType_End){
// 保存当前节点
del_node = iter;
// 迭代器后移动
iter = iter->next[0];
// 删除掉当前的数据节点
if(del_node->type == nodeType_Data){
delete del_node;
}
}
// 把跳表的大小设置为 0
this->size = 0;
// 经过while循环,此时的 iter 指向的一定是终止节点!
// 更新head节点里面的数据
for (int i = 0; i < MAX_Level; i++)
{
head->next[i] = iter;
}
// 完成清理!
}
template<typename K, typename V>
void Skiplist<K,V>::tranverse(){
std::cout << "####################\n";
Node<K,V>* iter = head;
while(iter->type != nodeType_End){
if(iter->type == nodeType_Head){
std::cout << "Head level [";
for(size_t i = 0; i < iter->next.size(); i++){
if(iter->next[i]->type == nodeType_End)
std::cout << "END, ";
else if(iter->next[i]->type == nodeType_Data)
std::cout << iter->next[i]->key << ", ";
else if(iter->next[i]->type == nodeType_Head)
std::cout << "Head, ";
}
std::cout << "]" << std::endl;
iter = iter->next[0];
continue;
}
// 输出当前的值
// std::cout << "key: " << iter->key << " value: " << iter->val;
std::cout << "key: " << iter->key << " value: [ingore]";
std::cout << " level[ ";
for(size_t i = 0; i < iter->next.size(); i++){
if(iter->next[i]->type == nodeType_End)
std::cout << "END, ";
else if(iter->next[i]->type == nodeType_Data)
std::cout << iter->next[i]->key << ", ";
else if(iter->next[i]->type == nodeType_Head)
std::cout << "Head, ";
}
std::cout << "]" << std::endl;
// 迭代器后移动
iter = iter->next[0];
}
}
template<typename K, typename V>
void Skiplist<K,V>::copyAll(std::list<std::pair<K, V> > &list){
Node<K,V>* iter = head;
while(iter->type != nodeType_End){
if(iter->type == nodeType_Data){
list.push_back({iter->key, iter->val});
}
// 迭代器后移动
iter = iter->next[0];
}
}
/**
* 对外暴露的插入函数
*/
template<typename K, typename V>
Node<K,V>* Skiplist<K,V>::insert(K elemKey, V elemVal){
// 插入节点
return this->insertNode(elemKey, elemVal);
}
/**
* 对外暴露的查找函数
*/
template<typename K, typename V>
Node<K,V>* Skiplist<K,V>::find(K elemKey){
return this->findNode(elemKey);
}
/**
* 对外暴露的删除函数
*/
template<typename K, typename V>
void Skiplist<K,V>::remove(K elemKey){
// 删除节点
this->deleteNode(elemKey);
}
五、跳表面试题
相比较红黑树,为什么Redis使用跳表而不是用红黑树?
- 我查阅了Redis作者的回答,大致说三个方面。
- 首先,跳表不是一个内存密集型的存储结构。我可以设置跳表的层数限制,往上增长楼层的概率,来控制对于内存的占用。这样下来我可以通过配置参数,使得内存占用甚至比一些BTree更少。
- 然后,作为一个键值对存储系统,可能需要经常扫描某一个范围的Key,至少来说跳表的时间复杂度和其他的树结构的存储,性能可以比肩。
- 实现简单,Debug方便。相比较树结构存储的遍历的复杂程度,我只需要输出level-0的所有元素即可遍历跳表,所以很方便调试。